
W poprzednim artykule pisałem o „Trzech rzeczach, które powinieneś wiedzieć o Hibernate”. Dzisiaj zajmę się szczegółowym opisaniem pierwszej z nich, czyli problemem n + 1 zapytań.
Problem ten dotyczy pobierania kolekcji powiązanych w relacji z daną encją (najczęściej) jeden-do-wielu (one-to-many). Jest to bardzo podstawowy problem, ponieważ relacje one-to-many, to jedna z najczęściej wykorzystywanych relacji.
Z czego wynika problem N + 1 ?
Wiele lat temu gdy zaczynałem swoją przygodę z Hibernate, natrafiłem na mniej więcej takie stwierdzenie:
„Z pomocą Hibernate można tworzyć aplikacje oparte o bazę danych nie znając sqla i baz danych”.
Nie jest to prawda. Bez podstawowej wiedzy z zakresu baz danych i sql ciężko jest budować dobrze działające aplikacje.
Programiści, którzy pokładają dużą wiarę w to, że narzędzie zrobi za nich wszystko i to w dodatku „tak jak trzeba”, często właśnie wpadają w pułapkę N+1. A najczęściej spotykanymi przyczynami tego problemu są: niewiedza i/lub niedbałość w realizowaniu zadań (to przyczyny, z którymi ja często mam do czynienia).
Pokazuje to pewną zależność: nie wystarczy umieć używać narzędzia, trzeba także znać szczegóły jego implementacji i mieć je ciągle z tyłu głowy.
Jakie są konsekwencje ?
Problem ten powoduje drastyczny spadek wydajności wynikający z generowania bardzo dużej ilości zapytań sql. W zależności od sytuacji, tych zapytań może być kilka lub nawet kilka tysięcy. Generalnie nie jest to duży problemem, jeśli dzieje się to w twoim środowisku developerskim, ponieważ z reguły masz w nim niewielką ilość danych, więc trudno to nawet zauważyć. Natomiast wszystko komplikuje się, gdy aplikacja zaczyna działać w środowisku produkcyjnym, gdzie zwykle jest dużo większa ilość danych „testowych”. A także w przypadku, kiedy aplikacji używa co najmniej kilku użytkowników jednocześnie. Dlatego warto przygotowywać środowisko testowe, które jest chociaż częściowo zbliżone do produkcyjnego.
Jak wykryć problem N+1 zapytań ?
Najłatwiej wykryć ten problem poprzez logowanie zapytań sql wykonywanych przez Hibernate’a (pamiętaj, że nie jest to zalecane na produkcji). Służy do tego properties show_sql. Ja w przykładowej aplikacji skorzystam ze Spring Boota i Spring Data, a taki properties można ustawić w application.properties:
spring.jpa.show-sql=true
lub jako parametr przy uruchamianiu aplikacji:
--spring.jpa.show-sql=true
Możesz także, włączyć statystyki sesji Hibernate:
spring.jpa.properties.hibernate.generate_statistics=true
Przykładowa implementacja
Załóżmy, że musimy pobrać z bazy danych listę wszystkich użytkowników wraz z ich adresami. W bazie mamy 10 użytkowników i każdy z nich ma po 5 adresów.
Encja User reprezentuje naszego użytkownika oraz zawiera powiązaną listę adresów:
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
private String username;
@OneToMany
@JoinColumn(name = "userId")
private List<Address> addresses;
// ... getters and setters
}Encja Address reprezentuje adres użytkownika:
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
private Long userId;
private String street;
private String zipCode;
private String city;
// ... getters and setters
}Gdy próbujemy pobrać za pomocą Hibernate’a listę użytkowników, to Hibernate domyślnie pobiera nam tylko listę użytkowników (1 zapytanie). Jeśli pod czas trwania sesji Hibernate’a spróbujemy pobrać listę adresów wszystkich użytkowników (używając metody user.getAddresses()), to Hibernate wykona dodatkowo po jednym zapytaniu dla każdego użytkownika (n – zapytań, n to liczba użytkowników). W takiej sytuacji Hibernate wykona 11 zapytań.
Przykładowe zapytanie JPQL(Java Persistence Query Language) dla listy użytkowników wyglądałoby tak:
select u from User u
W Spring Data wystarczy, że użyjemy metody findAll z repozytorium użytkowników. Metoda ta wykonuje to samo zapytanie, co powyżej. Dzięki spring data nie musimy podawać go jawnie.
Udostępnieniem tych użytkowników zajmie się kontroler:
@RestController
public class NplusOneController {
private final NplusOneUserRepository nplusOneUserRepository;
public NplusOneController(NplusOneUserRepository nplusOneUserRepository) {
this.nplusOneUserRepository = nplusOneUserRepository;
}
@GetMapping("/np1/users")
public List<NplusOneUser> getUsers() {
return nplusOneUserRepository.findAll();
}
}Żeby wywołać taką usługę, wystarczy odpalić w konsoli komendę:
curl -s localhost:8080/np1/users
Jak widać w logu, Hibernate wykonuje 11 zapytań:
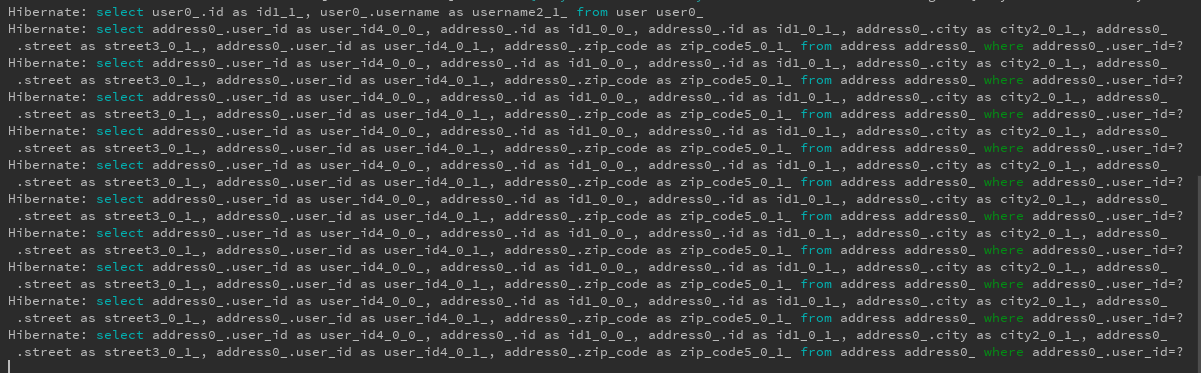
Jak poradzić sobie z problemem N+1 zapytań ?
Użyj BatchSize
Rozwiązań jest kilka, pierwsze z nich to ustawienie adnotacji @BatchSize z odpowiednio dobranym parametrem size.
@OneToMany @JoinColumn(name = "userId") @BatchSize(size = 5) private List<BatchSizeAddress> addresses;
Spowoduje to, że powiązane encje będą pobierane porcjami. Przykładowo jeśli mamy 10 użytkowników i każdy z nich ma po 5 adresów (czyli w bazie mamy 50 adresów), to żeby pobrać wszystkie adresy dla tych użytkowników, będziemy potrzebowali 2 dodatkowe zapytania (zamiast 10 wcześniejszych). Ustawiając size na 10 lub więcej, będzie to 1 dodatkowe zapytanie.
Nie jest to rozwiązanie idealne, ale w niektórych przypadkach sprawdzi się doskonale.
Żeby wywołać usługę prezentującą ten przykład, wystarczy uruchomić:
curl -s localhost:8080/bs/users
Przy takim ustawieniu Hibernate wykonuje tylko 3 zapytania:

Użyj zapytanie JPQL wraz z Join Fetch
Kolejne rozwiązanie, to pobranie użytkowników wraz z adresami jednym zapytaniem, przy użyciu Join Fetch:
select u from JoinFetchUser u join fetch u.addresses
Dodatkowo musimy zadbać o unikalność wyników. Robimy to dlatego, że Hibernate przekształci takie zapytanie na select z joinem, który zwróci nam 50 wierszy wyników, po czym przekształci to do listy 50 użytkowników wraz z adresami.
Unikalność wyników możemy zapewnić na dwa sposoby:
- Stosują słowo kluczowe distinct w zapytaniu (będziemy musieli nadpisać metodę
findAllz repozytorium użytkowników) - Zamiast zwracać listę użytkowników, zwracamy
Set(będziemy musieli zrobić nową metodę w repozytorium użytkowników)
Ja skorzystam ze słowa kluczowego distinct.
select distinct u from JoinFetchUser u join fetch u.addresses
A poniżej nadpisana metoda findAll:
@Override
@Query("select distinct u from JoinFetchUser u join fetch u.addresses")
List<JoinFetchUser> findAll();W tym wypadku pobieramy wszystkich użytkowników wraz z adresami (jednym zapytaniem sql), co w większości przypadków jest całkiem dobrym i wydajnym rozwiązaniem.
Jest to zalecane rozwiązanie, tego problemu.
Żeby wywołać usługę prezentującą, ten przykład wystarczy uruchomić:
curl -s localhost:8080/jf/users
Dla takiego zapytania JPQL Hibernate generuje nam poniższe zapytanie select wraz z joinem:

W poniższym filmie przedstawiam m.in. jak działa problem N+1 w Hibernate gdy korzystamy ze Spring Data. Pokazuję także na dwa sposoby, jak można się go pozbyć.
Podsumowanie
W tym artykułem starałem się szczegółowo zapoznać Cię z problemem n+1 i ze sposobami jego rozwiązania. Mam nadzieję, że udało mi się chociaż trochę przybliżyć ten problem. Kody źródłowe do testowej aplikacji, można znaleźć na githubie: Hibernate Example.






Hej, a co myślisz o modularnym monolicie? Czyli wszystko jak najbardziej rozdzielone nie mamy relacji w modelu encji jedyna relacja to na listę idków? Wtedy pytamy tylko o to czego potrzebujemy.
Modularny monolit jest jak najbardziej ok. Ale to nie oznacza, że w modelu nie masz relacji. Możesz mieć jak najbardziej relacje w modelu, chodzi o to żeby moduły nie były ze sobą ściśle powiązane. I najlepiej żeby ze sobą gadały przez jakieś wydzielone api (tak, żeby nie współdzieliły encji bazodanowych czy samego modelu). Natomiast w obrębie danego modułu możesz robić „co chcesz”. W praktyce trudno jest osiągnąć taką modularność z tego względu, że wszyscy programiści w zespole muszą tego pilnować i muszą mieć dosyć dobre zrozumienie tematu. Dlatego zdecydowanie częściej można spotkać niemodularne monolity i rozproszone niemodularne monolity, które generalnie są porażką 😉
Jak najbardziej się zgadzam z tym co napisałeś. Sam jak robię moduły to z myślą żeby móc z nich później wydzielić mikro usługi. Wszystko jak najmocniej hermetyzuje wystawiając fasadę która daje dostęp do tego co potrzebne. Takie podejście zmniejsza ryzyko n+1 do minimum.
Nie dostałem powiadomienia że odpisałeś dlatego odpowiadam po takim czasie.
Dzięki za komentarz Szymon
Chyba coś nie zadziałało, być może mam źle skonfigurowany plugin.
JoinFetchUser to jest nowa klasa ?
Tak to klasa. Zajrzyj na githuba, jest link na samym końcu artykułu.
Przy JoinFetchu napisałeś : „Zamiast zwracać listę użytkowników, zwracamy Set (będziemy musieli zrobić nową metodę w repozytorium użytkowników)”, a w kodzie widzę dalej Listę..?
„Unikalność wyników możemy zapewnić na dwa sposoby:”, a po wypunktowaniu jest napisane „Ja skorzystam ze słowa kluczowego distinct” – te dwa sposoby są rozłączne, nie musisz korzystać z tego i tego (ale oczywiście możesz).
rozwiązanie z join fetchem prowadzi do „eksplozji” wyników, hibernate nawet rzuca warning w tym wypadku. dla większych listingów to rozwiązanie absolutnie nie jest optymalne.
Po prostu rozwiązując jeden problem, napotkałeś na inny. Join Fetch sam w sobie nie jest źródłem problemu. Jeśli twoje zapytanie prowadzi do „eksplozji” to prawdopodobnie zapytanie zwraca produkt kartezjański(iloczyn kartezjański) i takie zachowanie jest specyficzne dla baz danych, po prostu tak baza zwraca wyniki złączeń. Nie ma co winić join fetcha 😉
Rozwiązanie to podzielenie jednego wielkiego zapytania, na kilka mniejszych z join Fetchami. Ale najpierw polecam poczytać skąd bierze się ten problem.
jeden select po encję bazową i po jednym seleccie na każde encje -to-Many, które mamy pobrać. potem zlepianie w całość w jakiś projekcjach czy view modelach. dzięki temu możemy ogranicznyć ilość zapytań do X+1, gdzie X to ilość kolekcji do pobrania. działa nawet dla bardzo dużych list. niestety, wymaga ręcznej pracy.
Ostatnio natrafiłem na rozwiązanie palącego problemu N+1.
Normalnie zachowujemy nasze fetch = FetchType.LAZY, z tym że nadpisujemy metode z repozyturium i nad nią dodajemy adnotacje @EntityGraph, definiując dodatkowo pole które chcemy „zgrafować”. Dzięki czemu Hibernate sam za nas zrobi LEFT OUTER JOIN, wykonując wszystko w jednym zapytaniu 🙂
adnotacja z pakietu org.springframework.data.jpa.repository.EntityGraph;
Można też tak 😉 Tak naprawdę jest kilka sposobów na rozwiązanie tego problemu w Hibernate.
Super odcinek, jak i inne zresztą też.
Kompleksowo wyjaśniony problem i zaprezentowane najbardziej naturalne rowiązanie.
Bardzo ciekawe opracowanie.
Zalecane jest rozwiązanie przy wykorzystaniu join fetch.
Co w przypadku gdy musimy dołączyć więcej niż jedną tabelę.
Załóżmy dodanie do User’a:
@OneToMany
@JoinColumn(name = „detailId”)
private List details;
W repozytorium:
@Override
@Query(„select distinct u from JoinFetchUser u join fetch u.addresses join fetch u.details”)
List findAll();
Niestety to nie zadziała, ponieważ join fetch nie pozwala na łączenie 3 tabel.
Jakie rozwiązanie w takim przypadku zastosować?
Pozwala. Możesz łączyć ile tabel chcesz za pomocą join fetch, tylko nie możesz używać do tego List, bo dostaniesz błąd. Najprościej zmienić listę na Set i to pomoże pozbyć się błędu. Ale z kolei możesz wpaść w kolejną pułapkę, czyli problem iloczynu kartezjańskiego. Zarówno problem iloczynu kartezjańskeigo jak i problem n+1. Omawiam w moim kursie Hibernate i JPA, szczegóły znajdziesz tutaj